How On-Device AI Text Summarization Works Internally on Android
June 23, 2026

Artificial Intelligence has rapidly transformed the way mobile applications process and understand text. One of the most useful applications of AI on smartphones is text summarization, where lengthy articles, notes, emails, or documents are condensed into concise summaries.
Traditionally, text summarization relied on cloud-based servers. However, modern Android devices are increasingly capable of running AI models directly on the device itself, enabling On-Device AI Summarization.
This article explores the complete internal workflow of on-device text summarization in Android, from user input to summary generation.
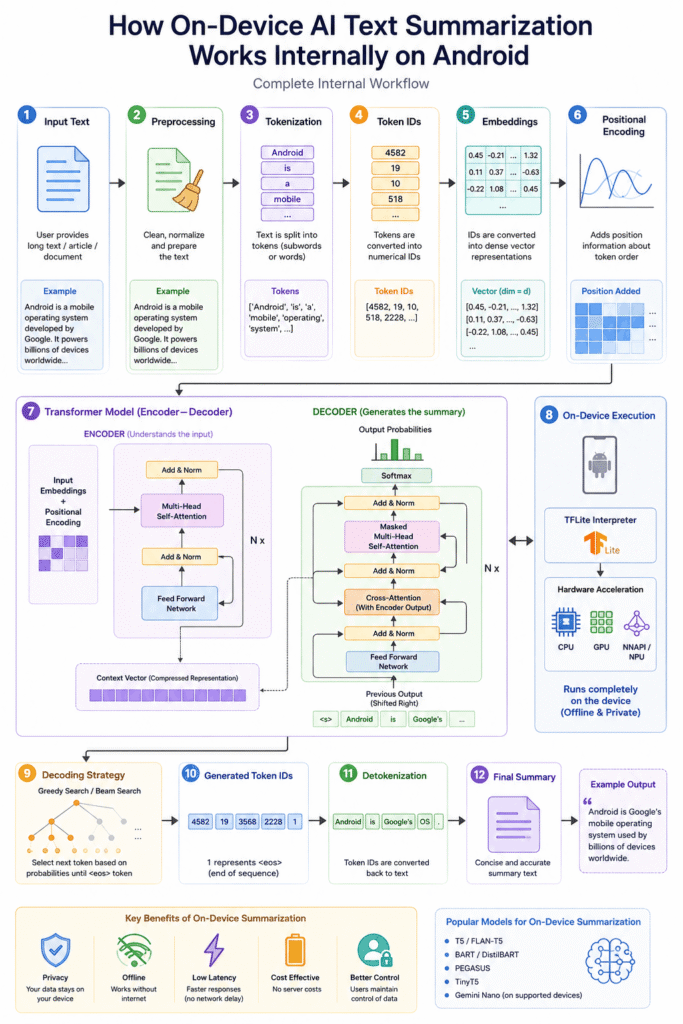
What is On-Device AI?
On-device AI refers to executing machine learning or deep learning models directly on a user’s smartphone without sending data to external servers.
Instead of:
User Input → Internet → Cloud AI → SummaryThe process becomes:
User Input → Local AI Model → SummaryEverything happens inside the device, offering significant advantages:
- Better privacy
- Offline functionality
- Lower latency
- Reduced server costs
- Improved responsiveness
Understanding Text Summarization
Text summarization is the process of reducing large amounts of text while preserving its key information.
Example
Input:
Android is a mobile operating system developed by Google. It powers billions of smartphones, tablets, televisions, wearables, and other smart devices around the world.
Summary:
Android is Google’s operating system used by billions of devices worldwide.
The AI model identifies the most important information and generates a shorter version.
The Complete Summarization Pipeline
Internally, the process follows several stages:
Input Text
↓
Preprocessing
↓
Tokenization
↓
Embedding Generation
↓
Transformer Processing
↓
Summary Generation
↓
Detokenization
↓
Final SummaryEach stage plays a critical role in producing accurate summaries.
Step 1: User Provides Text
The process begins when the user enters or selects content.
Examples include:
- Articles
- Emails
- Meeting notes
- Documents
- Chat conversations
At this stage, the text is simply a sequence of characters.
Example:
Artificial Intelligence is transforming healthcare by improving diagnostics and treatment planning.Computers cannot directly understand language. The text must first be converted into numerical representations.
Step 2: Text Preprocessing
Before entering the AI model, the text is cleaned and normalized.
Common preprocessing tasks include:
- Removing extra spaces
- Standardizing punctuation
- Handling special characters
- Converting text formats
Example:
Hello World!!!becomes:
Hello World!This helps ensure consistent model performance.
Step 3: Tokenization
AI models do not process words directly.
Instead, they process tokens.
A token can be:
- A word
- Part of a word
- A character
- A subword fragment
Example
Input:
Android is amazingTokenized as:
["Android", "is", "amazing"]Or sometimes:
["And", "roid", "is", "amaz", "ing"]depending on the tokenizer.
Why Tokenization Matters
Language contains millions of possible words.
Instead of memorizing every word, modern AI systems use subword tokenization techniques such as:
Byte Pair Encoding (BPE)
Commonly used by GPT-style models.
WordPiece
Used by BERT.
SentencePiece
Frequently used by T5 and many mobile-friendly transformer models.
This approach dramatically reduces vocabulary size while maintaining language understanding.
Step 4: Converting Tokens into IDs
Each token receives a numerical identifier.
Example:
Android → 4582
is → 19
amazing → 3657Result:
[4582, 19, 3657]The AI model now works entirely with numbers.
Step 5: Embedding Layer
Token IDs themselves have no meaning.
The embedding layer transforms each token into a dense mathematical representation.
Example:
4582becomes:
[0.45, -0.12, 1.32, 0.87, ...]These vectors may contain hundreds of dimensions.
Words with similar meanings end up closer together in this mathematical space.
For example:
King
Queen
Prince
Princessdevelop related vector patterns.
Step 6: Positional Encoding
Transformers process tokens simultaneously.
However, language depends heavily on word order.
Compare:
Dog bites manand
Man bites dogThe same words appear, but the meaning changes completely.
Positional encoding introduces information about token order.
This allows the model to understand sentence structure.
Step 7: Transformer Architecture
Modern summarization models rely heavily on the Transformer architecture.
Popular examples include:
- T5
- BART
- PEGASUS
- FLAN-T5
Transformers revolutionized natural language processing by introducing the concept of attention.
Step 8: Self-Attention Mechanism
Self-attention enables a model to determine which words are most important when understanding a sentence.
Consider:
The cat sat on the mat because it was tired.The word:
itrefers to:
catThe attention mechanism helps the model learn this relationship.
Query, Key, and Value
Internally, each token generates:
- Query (Q)
- Key (K)
- Value (V)
The model compares:
Query × Keyto calculate relevance.
Tokens with higher relevance receive greater attention.
This enables contextual understanding across long passages.
Step 9: Multi-Head Attention
Instead of using a single attention mechanism, transformers use multiple attention heads.
Each head learns different relationships.
For example:
Head 1
Grammar relationships.
Head 2
Subject-object relationships.
Head 3
Temporal information.
Head 4
Contextual meaning.
All heads work together to build a rich understanding of the input text.
Step 10: Encoder Processing
In encoder-decoder models like T5, the encoder reads the entire input text.
Example:
Long Article
↓
Encoder
↓
Context RepresentationThe encoder transforms the article into a compressed semantic representation.
This representation captures:
- Meaning
- Context
- Relationships
- Important facts
without storing the original text directly.
Step 11: Summary Generation (Decoder)
Once the encoder finishes, the decoder begins generating the summary.
The summary is generated one token at a time.
Example:
Iteration 1
AndroidIteration 2
Android isIteration 3
Android is Google'sIteration 4
Android is Google's mobile operating system.This continues until an end-of-sequence token appears.
Step 12: Decoding Strategies
The AI must decide which token to generate next.
Several strategies exist.
Greedy Search
Always select the most probable token.
Simple and fast.
Beam Search
Maintains multiple candidate summaries simultaneously.
More accurate but computationally expensive.
Sampling
Introduces randomness for creativity.
Less common in summarization.
For mobile devices, greedy search and small beam sizes are typically preferred due to resource constraints.
Step 13: Detokenization
Generated tokens are converted back into readable text.
Example:
[4582, 19, 3456]becomes:
Android is popularThis is known as detokenization.
The resulting text becomes the final summary displayed to the user.
Hardware Acceleration on Android
AI inference can run on several hardware components.
CPU
Most compatible.
Works on all devices.
GPU
Provides faster matrix calculations.
Useful for larger models.
Neural Processing Unit (NPU)
Specialized AI hardware.
Found in many modern smartphones.
Provides:
- Faster inference
- Lower battery consumption
- Better performance
Android AI frameworks can automatically choose the best execution path.
Role of TensorFlow Lite
The most common framework for on-device AI on Android is:
TensorFlow Lite
TensorFlow Lite:
- Optimizes models for mobile devices
- Reduces memory consumption
- Supports hardware acceleration
- Enables offline AI processing
A model trained on powerful cloud GPUs can be converted into a lightweight TFLite format for Android deployment.
Memory and Performance Challenges
Text summarization models are significantly larger than traditional machine learning models.
Common challenges include:
Model Size
Some transformer models exceed hundreds of megabytes.
RAM Usage
Attention layers consume substantial memory.
Inference Time
Generating summaries requires multiple decoding iterations.
Battery Consumption
Long-running inference tasks can increase power usage.
To address these issues, developers often use:
- Quantization
- Model pruning
- Distillation
- Smaller transformer architectures
Advantages of On-Device Summarization
Privacy
Sensitive documents never leave the device.
Offline Support
Works without internet connectivity.
Faster Response
No network latency.
Lower Costs
No server infrastructure required.
Better User Trust
Users maintain control over their data.
Limitations
Despite its advantages, on-device summarization still has limitations.
Smaller Models
Mobile devices cannot always run large language models.
Hardware Variability
Performance differs across devices.
Limited Context Length
Memory constraints often reduce maximum input size.
Slower Generation
Compared to cloud-based GPU clusters.
Future of On-Device Summarization
Modern smartphones are rapidly becoming AI-first devices.
Technologies shaping the future include:
- On-device Large Language Models (LLMs)
- Edge AI acceleration
- Hybrid AI (device + cloud)
- Personalized local models
- Real-time document understanding
As mobile hardware continues to evolve, smartphones will increasingly perform advanced natural language processing tasks without relying on cloud services.
Conclusion
On-device AI text summarization is a sophisticated process involving tokenization, embeddings, transformer-based language understanding, attention mechanisms, and sequential text generation. Rather than sending data to remote servers, modern Android devices can now perform these computations locally using optimized AI frameworks and specialized hardware accelerators.
The result is a powerful combination of privacy, speed, offline functionality, and intelligent text understanding—making on-device summarization one of the most impactful applications of AI in modern Android development.